一、从函数到神经网络#
函数:描述了一种输入与输出之间的映射关系
线性函数:激活函数:常用的激活函数:f(x)=wx+b, w是权重,b是偏置f(x)=g(wx+b)g(x)=1+e−z1, ReLU(z)=max(0,z)由于数据分布不均匀时,线性函数无法拟合真实数据,需要使用非线性函数。在线性函数外层套一层激活函数,就可以将原本的线性函数变成表达能力更强的非线性函数。
神经网络
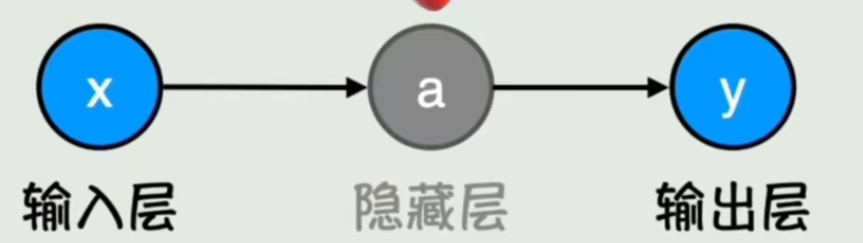
f(x)=g(wx+b)只有一个输入时如上式。
输入变多后:
f(x)=g(w1x1+w2x2+b)在原函数基础上再套一层激活函数:
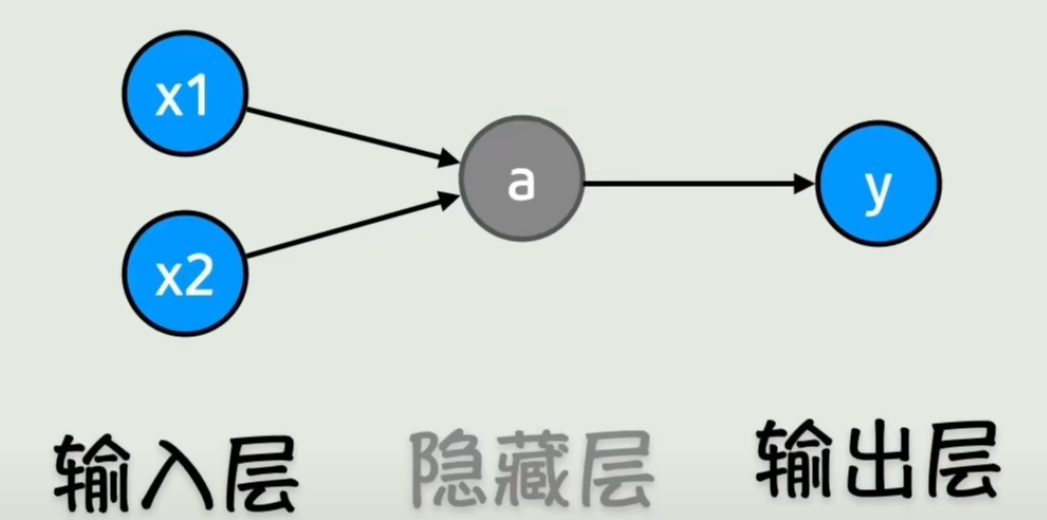
f(x)=g(w3(g(w1x1+w2x2+b))+b)f(x)f1(x)=g(w3f1(x)+b)=g(w1x1+w2x2+b)=y此时 f1 这一层就称为隐藏层。
 img
img由大量神经元组成的网络结构,我们称之为神经网络。
前向传播:在神经网络中从左到右、从输入到输出,逐步计算函数值的过程。
二、计算神经网络的参数#
判断神经网络训练好坏,就是看它与真实数据的拟合程度。
用数学语言描述拟合好坏:已知 f(x)=wx+b,我们希望求出合适的 w 和 b。
每个数据点上,竖直方向的长度就是真实值与预测值之间的误差。
将所有误差汇总,就能反映整体拟合效果。
数据:线性模型:误差:损失函数:均方误差(MSE):目标:(x1,y1),(x2,y2)y=wx+b∣y−y^∣k=1∑n∣yk−y^k∣N1k=1∑N(yk−y^k)2=L(w,b)求解让 L 最小的 w,b求解思路:对损失函数中的 w 和 b 求偏导,令导数为 0,求极值点。
实战示例:
数据:(1,1), (2,2), (3,3), (4,4)线性模型:y=wxL(w)L′(w)w=N1k=1∑N(yk−wxk)2=41[(1−w)2+(2−2w)2+(3−3w)2+(4−4w)2]=41(30−60w+30w2)=7.5−15w+7.5w2=−15+15w=0=1这种用线性函数拟合 x 与 y 关系的方法,就是机器学习中最基础的线性回归。
神经网络是由大量线性函数与非线性激活函数组合成的复杂非线性函数,对应的损失函数通常无法直接令导数为 0 求解。
假设当前 w,b 为 5,损失函数为 10。
w 微小变化带来损失函数的变化,就是损失对 w 的偏导数,b 同理。
我们让 w,b 往偏导数的反方向更新。
w=w−η∂w∂L(w,b)b=b−η∂b∂L(w,b)其中 η 称为学习率,用来控制参数更新的步长。
这些偏导数组成的向量称为梯度。
不断更新 w,b、使损失函数逐渐减小的过程,称为梯度下降。
对于深层神经网络,直接求导非常困难,但层与层之间关系简单,可以使用链式法则。
 imgF1=g(w1x+b1)F2=g(w2a+b2)F3=(y−y^)2
imgF1=g(w1x+b1)F2=g(w2a+b2)F3=(y−y^)2以 w1 为例,损失 L 对 w1 的偏导:
∂w1∂L=∂y^∂L∂a∂y^∂w1∂a这种分段求导再相乘的方式,称为链式法则。
从输出层往输入层方向,逐层求导并更新参数,称为反向传播。
总结:
- 前向传播:根据输入 x 计算输出 y^
- 反向传播:计算损失对各参数的梯度
- 用梯度下降更新参数
这一整套流程,就是神经网络的一次训练。
三、调教神经网络的方法#
过拟合:模型在训练集上表现极好,但在未见过的测试数据上表现很差。
泛化能力:模型在未见过数据上的表现能力。
过拟合原因:模型过于复杂,把训练数据中的噪声和随机波动也学到了。
解决过拟合常用方法
从模型本身入手:
- 简化模型复杂度
- 增加数据量,或使用数据增强(旋转、翻转、裁剪、加噪声等),提升鲁棒性
从训练阶段入手:
- 提前终止训练
- 正则化:在损失函数中加入惩罚项,抑制参数过大
新损失函数=原损失函数+λi=1∑N∣wi∣(L1正则化)新损失函数=原损失函数+λi=1∑Nwi2(L2正则化)
- λ:正则化系数
- ∑∣wi∣:L1 范数
- ∑wi2:L2 范数
四、从矩阵到CNN#
当输入输出维度很高时,用矩阵表示更简洁:
y1y2=g(w11x1+w12x2+w13x3+b1)=g(w21x1+w22x2+w23x3+b2)写成矩阵形式:
[y1y2]=[w11w21w12w22w13w23]x1x2x3+[b1b2]用 L 表示层数:
Y=g(W[L]A[L−1]+b[L])全连接层:可以整合全局信息,但参数量巨大,容易过拟合。
卷积层:用卷积核滑动提取局部特征,是 CNN 的核心。
池化层:对特征图降维,减少计算量,保留关键信息。
这种用于图像的网络结构,称为卷积神经网络 CNN。
CNN 更适合处理静态数据(如图像)。
要处理时序数据(文本、语音、视频等),就需要用到 Transformer。


 Lirael's Tech Firefly
Lirael's Tech Firefly